Deploying GPT-5 in Unify for scaled GTM research
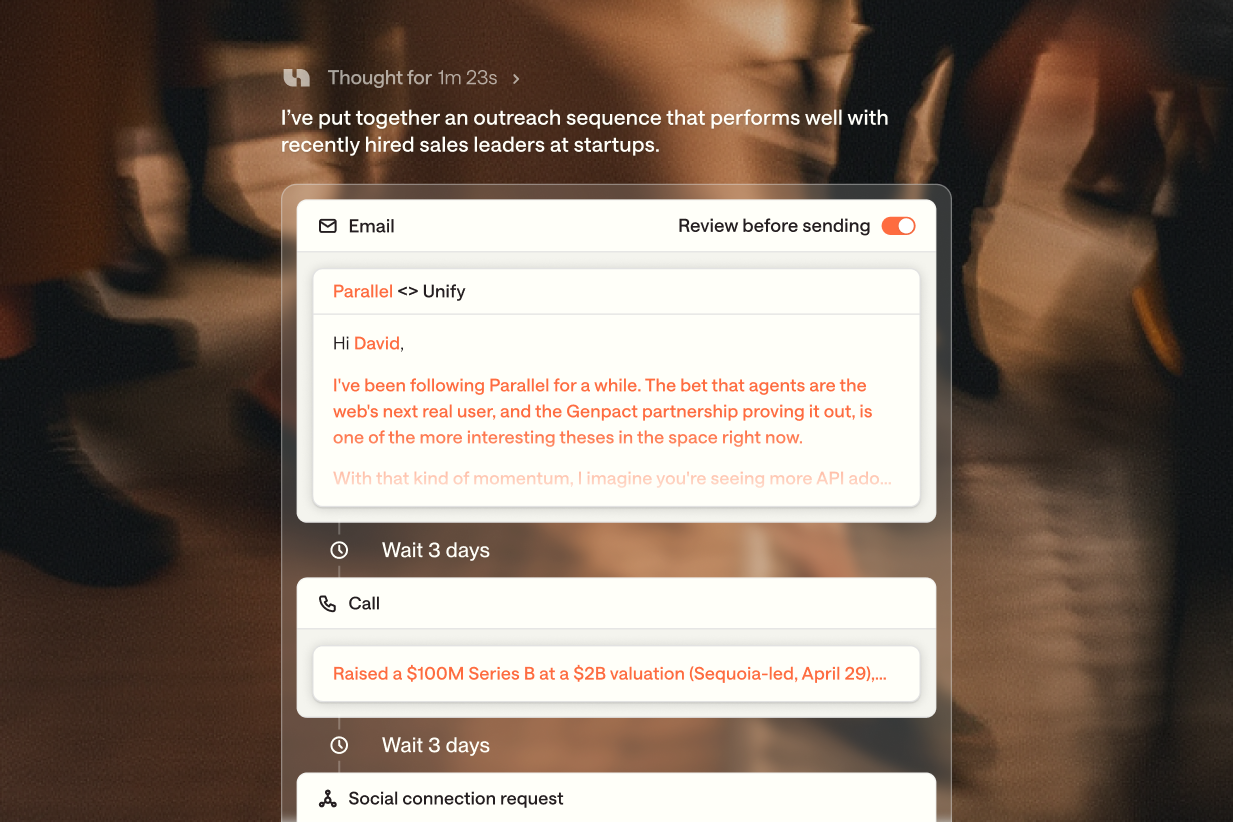
When we launched the Unify Observation Model this June, we shared our thesis that go-to-market is fundamentally a search problem: find people and companies that have a problem your product uniquely solves. Over the last two months, we’ve gotten feedback from customers that they’ve been amazed by the power of the Observation Model, previously powered by o3 and now GPT-5, to understand the unique signals and attributes of prospects their business cares most about. Reps open their laptops every morning to a dashboard full of prospects, with tailored context on exactly why they are a great fit.
With GPT-5, we’ve taken this to the next level. We are publicly exposing our Observation Model in our new AI Lead Generation tool, which takes in simple information (name and website) about your business, deeply researches your company, and surfaces high fit leads and unique context about how you should sell to them. Try it today here, and see the future of running your GTM motion with AI at scale.
Evaluating GPT-5’s strengths
We've had the chance to work with OpenAI and be early testers of the gpt-5 suite of models over the last few weeks. From our evaluations, we are most excited about the improvements to agentic research, agentic browser use, and overall steerability of the models.
For our use cases in qualification and general internet search, we found gpt-5 and gpt-5-mini to be the most effective across our evals. GPT-5 matched or exceeded o3 in accuracy and tool calling efficiency while GPT-5-mini matched or exceeded GPT-4.1. What was most notable from these evaluations is the configuration that is possible with the new verbosity parameters in conjunction with reasoning effort and system prompts. All models evaluated were run using tool calling in chain of thought when applicable. Through evaluations while running a parameter sweep, we found that increases to verbosity negatively impacted tool calling efficiency but had no conclusive correlation with accuracy on tasks.
When testing the GPT-5 series we were surprised at how steerable the models were from adjustments to prompts in agentic settings. Compared to system prompts needed for previous models like o3 and GPT-4.1, simpler instructions on how the agent should operate effectively changed model performance. From the evaluation charts, we can see that between the original GPT-5 prompts we used from prior models and the improved prompts which focused on guiding the model to act in a specific way, we were able to cut tool calls made by 35% across our evaluations. The main changes in our prompting styles were to instruct the model to plan out how it can use the fewest number of tools to complete tasks and to focus on the order of tool calls for research to maximize the likelihood of success in the fewest steps possible. We anticipate that with further prompting, different characteristics of the model can be emphasized or muted to suit specific use cases better which has not been as adjustable in prior models.
We were also fans of the CUA model and had success with implementing it to conduct agentic browser tasks for research and qualification. However, the stability of browser agent runs (% successful attempts / total attempts) left room for improvement even with a custom implementation using Playwright. Across our evaluation suite for browser research tasks, CUA could solve 3/7 tasks with a stability of 67% across runs. We saw better performance in complex browser interactions (like navigating Google Maps), but the ability to reliably execute on exploratory browser interactions was limited with extended testing. As a result, we shifted from CUA to using SOTA reasoning and multi-modal models like Gemini 2.5, Claude 3.7, and GPT-4.1 for browser tasks. While on average stability improved to 75% with 4/7 tasks completed, we still saw task drift, where models would decide to investigate pop-ups, alternative search results, or get derailed after selecting the wrong UI element.
When running our browser evaluations against GPT-5, we were able to complete all 7 tasks with 90% stability between runs. Model drift was significantly reduced, and the model was able to use tabs and normal browser navigation much better (watch GPT-5 use inspect element to see if a company is using Auth0).


The most improved characteristic in browser interactions with GPT-5 was its ability to course correct quickly and exhibit human-like browser usage (terminating searches if search engine results looked bad, using search to navigate to new pages faster rather than trying to find the right web element on complex tasks). This resulted in average steps taken to complete a browser task reduced by 40%.
How our AI Lead Generation tool works

We wanted to create a simple UX to allow customers to see immediate value and the power of GPT-5 for go-to-market:
- Tell us who you are - all we need is a company name and domain (plus your email to send you the results).
- Understanding your company - GPT-5 analyzes your company’s website, pulls from our proprietary data sources, and uses other tools to understand what your company does, who your ideal customer profile is, and what your core value props are. This is surfaced to the user, so that you can make edits / tweaks with more context.
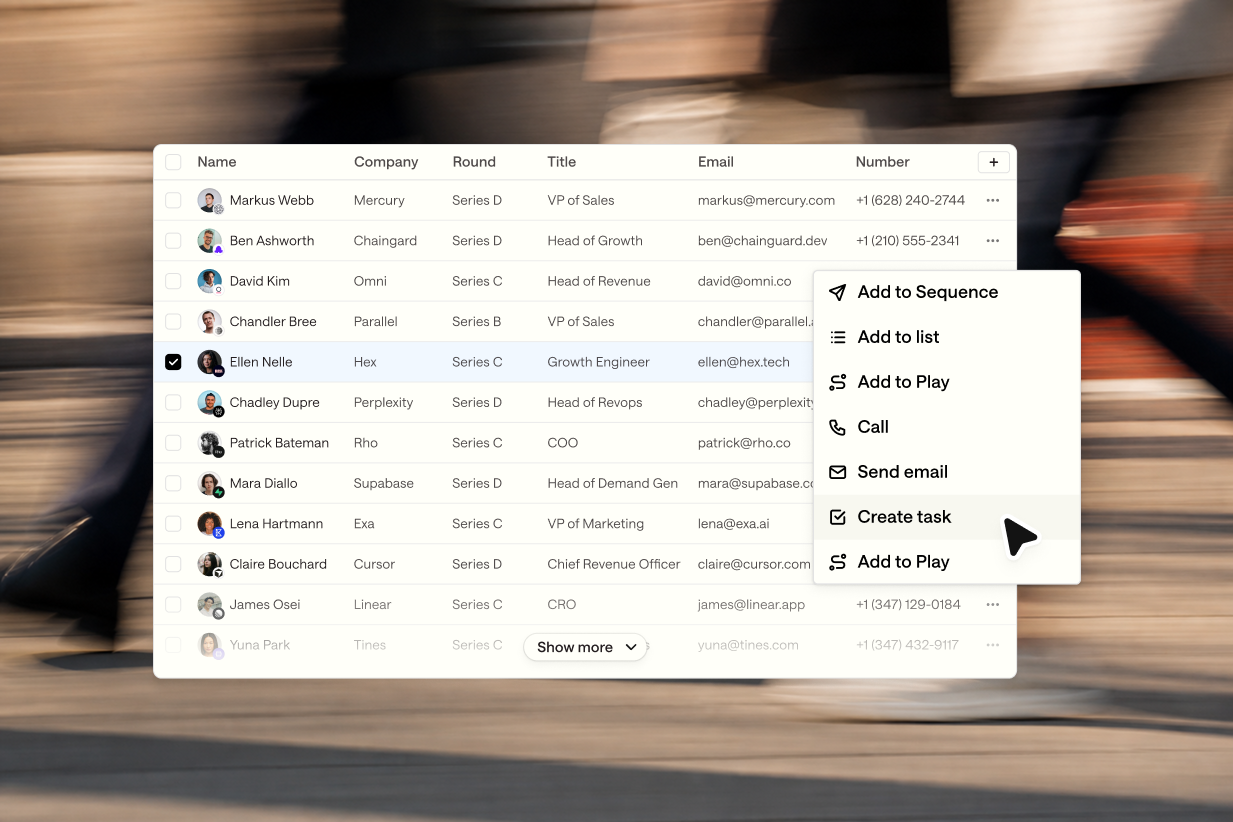
- Running the observation model on your TAM - Based on GPT-5’s understanding of your company and any additional details that you provide, the model reasons about what unique signals your company should look for to figure out if prospects have a problem you could solve. It then conducts a deep search, looking for custom signals to sift through and find companies that fit these criteria. After finding companies that fit this criteria, the model prioritizes the companies that emit the most important signals for your company.
- Leads and deep research in your inbox - You will receive a list of five accounts, the signals that triggered the match, and a full description and data about each company, all powered by GPT-5. Everything you need to craft the perfect touchpoint.
The lead generation tool is just a snapshot of the workflow that already lives inside Unify, where you can run this research across your entire TAM to find your next best-fit customers at scale. Let your reps focus on building human connections and relationships, rather than endless busywork. If you’re excited about deploying AI research to your GTM team, we would love to talk to you.
Our vision for Unify
Prior to LLMs, research of this precision and scale was run by armies of sellers but now it can be powered by agents doing the busywork while humans spend their time building meaningful connections. We believe that AI is driving a transformative shift in GTM, where finding new customers and engaging with them is aided by always-on agents.
We’ve already seen this come true with our customers that have driven $1.7M in pipeline in three months with zero BDRs or saved 20+ hours each week for their reps with Unify. We believe that humans will continue to leverage their unique ability to make connections and build relationships, but the busywork that used to take hours will be done by a system-of-action like Unify.
Our ultimate vision is to transform growth into a science and help the best products win. We are excited to continue to push what’s possible for our customers, and leveraging OpenAI’s models to power that future.
GPT-5 is live in our Lead Generation Tool and in product today, we’re excited to see what this powers for your team.